In the past few years, deep convolutional neural networks (ConvNets) have changed the field of computer vision because of their unparalleled ability to learn advanced semantic image features. However, in order to successfully learn these features, they typically require a large amount of manually labeled data, which is both expensive and impractical. Therefore, unsupervised semantic feature learning, that is, learning without the need for manual annotation work, is critical to the successful acquisition of a large amount of available visual data today.
In our study, we intend to learn image features in this way: training a convolutional neural network to identify two-dimensional rotations that are applied to the image as input. We prove from both qualitative and quantitative aspects that this seemingly simple task actually provides a very powerful monitoring signal for semantic feature learning. We have thoroughly evaluated our approach in a variety of unsupervised feature learning benchmarks and demonstrated the most advanced performance in all of these benchmarks.
Specifically, our results in these benchmarks show that in unsupervised characterization learning, our approach has been greatly improved over previous state-of-the-art methods, significantly reducing the gap between learning and supervised feature learning. For example, in the PASCAL VOC 2007 inspection mission, our unsupervised pre-trained AlexNet model achieved 54.4% of the most advanced performance (in an unsupervised approach), which was only 2.4 percentage points less than supervised learning. . When we moved unsupervised learning features to other tasks, we got the same amazing results, such as ImageNet classification, PASCAL classification, PASCAL segmentation, and CIFAR-10 classification. The code and model of our paper will be published here.
In recent years, deep convolutional neural networks, widely used in computer vision (proposed by LeCun et al. in 1998), have made tremendous progress in this area. Specifically, by successfully training convolutional neural networks on target recognition with a large amount of manually labeled data (reported by Russakovsky et al. in 2015) or by scene classification (Zhou et al.) in 2014, they have successfully learned A powerful visual representation of the task of image understanding.
For example, in this supervised manner, the image features learned by convolutional neural networks have achieved good results when they are migrated to other visual tasks, such as target detection (Girshick proposed in 2015), semantic segmentation (Long Et al., 2015, or image description (Karpathy and Fei-Fei were proposed in 2015). However, there is one major limitation to supervised feature learning, which is that it requires a lot of manual tagging work. This is expensive and impractical in the case of a large amount of visual data available today.

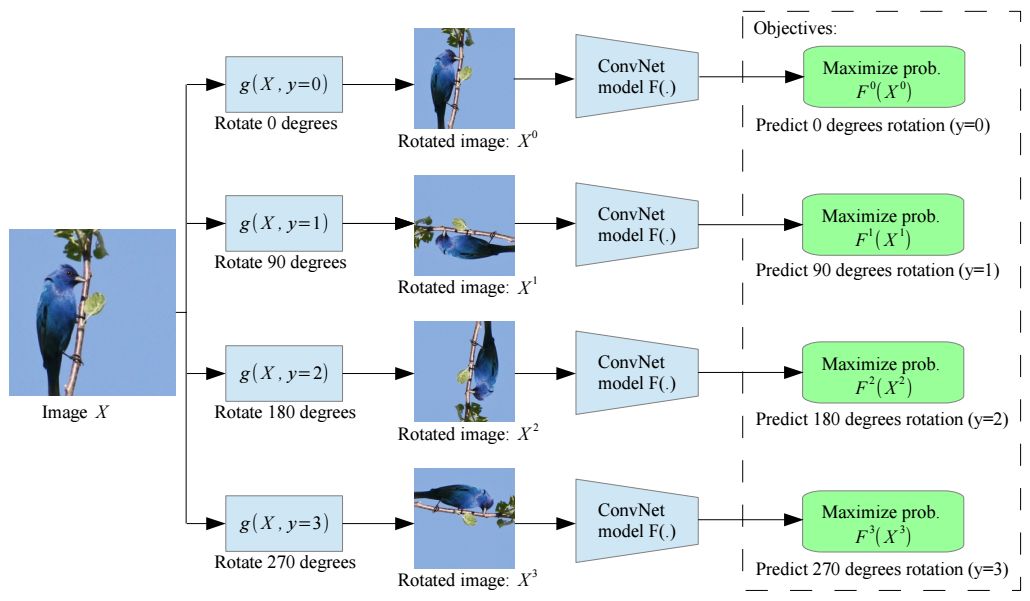
An image rotated at a random multiple of 90° (eg, 0°, 90°, 180°, 270°). The core idea of ​​our self-supervised feature learning approach is that if a person has no concept of the object described in the image, then he cannot recognize the rotation applied to them.
Therefore, there has recently been an increasing interest in learning advanced convolutional neural network based representations in an unsupervised manner, which avoids manual annotation of visual data. Among them, a prominent example is the so-called self-supervised learning, which defines an unconstrained excuse task, using only the visual information on the image or video, thus providing a proxy supervision signal for feature learning.
For example, in order to learn features, Zhang et al. and Larsson et al. trained convolutional neural networks to color grayscale images, and Doersch et al. (in 2015), Noroozi, and Favaro (in 2016) predicted the relativeity of image blocks. The location, and Agrawal et al. (in 2015) predicted the motion (ie, automatic) of the vehicle being moved between two consecutive frames.
The rationale behind this self-monitoring task is that solving these problems will force the convolutional neural network to learn semantic image features, which is useful for other visual tasks. In fact, the image representations learned through the above self-supervised tasks, although they are not comparable to the performance of supervised learning representations, have proven to be a good choice when migrating to other visual tasks, such as target recognition, target Detection and semantic segmentation. Other successful unsupervised feature learning cases are cluster-based methods, reconstruction-based methods, and methods for learning to generate probability models.
An illustration of the self-supervised task we propose for semantic feature learning
Our study follows a self-supervised paradigm and proposes to learn the image representation by training Convolutional Neural Networks (ConvNets) to identify the geometric transformations applied to its image as input. More specifically, first, we define a set of discrete geometric transformations, then apply each of these geometric transformations to each image on the dataset, and feed the resulting transformed image to trained to identify each The transformed image of the convolutional neural network model. In this method, it is a set of geometric transformations that actually define the classification pretext task that the convolutional neural network model must learn.
Therefore, in order to achieve unsupervised semantic feature learning, it is crucial to correctly select these geometric transformations. What we propose is to define geometric transformations as image rotations of 0°, 90°, 180°, and 270°. Therefore, the convolutional neural network model was trained on four image classification tasks that identified one of the four image rotations (see Figure 2). We believe that in order for a ConvNet model to recognize the rotation transform applied to an image, it needs to understand the concept of the objects described in the image (see Figure 1), such as their position, type, and pose in the image. Throughout the paper, we support this theory from qualitative and quantitative arguments.
In addition, we have experimentally proved that although our self-supervised method is simple, the task of predicting rotational transformation provides a powerful alternative supervised signal for feature learning. Significant progress has been made in related benchmarks.

An attention map generated by the AlexNet model, (a) trained to identify the target (supervised), and (b) trained to identify image rotation (self-supervised). To generate a note of the convolutional layer, we first compute the feature map for that layer, then we increase each feature activation on power p, and finally we sum the activation at each location of the feature map. For convolutional layers 1, 2 and 3, we use p = 1, p = 2, and p = 4, respectively.
It should be noted that our self-monitoring tasks are different from the research methods proposed by Dosovitskiy et al. in 2014 and Agrawal et al. in 2015, although they also involve geometric transformations. Dosovitskiy et al. trained a convolutional neural network model in 2014 to produce a discriminative representation of the image without changing the geometry and chrominance transformation. Instead, we train a convolutional neural network model to identify the geometric transformations applied to the image.
This is fundamentally different from the egomotion method proposed by Agrawal et al. in 2015, which uses a convolutional neural network model with a siemese structure that combines two consecutive videos. Frames are used as input and trained to predict (by regression) their camera transitions. Instead, in our approach, the convolutional neural network takes a single image as input, we have applied a random geometric transformation (rotation) and trained (by classification) to identify this geometric transformation without having to access the original image. .

The first layer of filters learned by the AlexNet model are trained in (a) supervising the target recognition task and (b) self-supervising tasks that identify the rotated image.
Our contribution:
• We proposed a new self-monitoring task that was very simple. At the same time, we also showed it in the article, providing a powerful monitoring signal for semantic feature learning.
• We have carefully evaluated our self-monitoring methods in a variety of environments (such as semi-supervised or migration learning environments) and various visual tasks (ie CIFAR-10, ImageNet, Places and PASCAL classification, and detection or segmentation tasks).
• Our new self-monitoring approach has demonstrated the most advanced results in all aspects, with significant improvements over previous unsupervised methods.
• Our research shows that for several important visual tasks, our self-supervised learning approach significantly narrows the gap between unsupervised and supervised feature learning.
After research, we propose a new method for self-supervised feature learning, which trains the convolutional neural network model to recognize image rotation that has been used as an input image. Although our self-monitoring task is simple, we have shown that it can successfully train convolutional neural network models to learn semantic features that are useful for various visual perception tasks such as target recognition, target detection, and target segmentation. .
We performed a detailed evaluation of our methods under various unsupervised and semi-supervised conditions and achieved the most advanced performance in the tests. Specifically, our self-monitoring method has significantly improved the latest results of unsupervised feature learning in ImageNet classification, PASCAL classification, PASCAL detection, PASCAL segmentation, and CIFAR-10 classification, surpassing previous methods, thus significantly reducing unsupervised And monitor the gap between feature learning.
Absolute rotary Encoder measure actual position by generating unique digital codes or bits (instead of pulses) that represent the encoder`s actual position. Single turn absolute encoders output codes that are repeated every full revolution and do not output data to indicate how many revolutions have been made. Multi-turn absolute encoders output a unique code for each shaft position through every rotation, up to 4096 revolutions. Unlike incremental encoders, absolute encoders will retain correct position even if power fails without homing at startup.
Absolute Encoder,Through Hollow Encoder,Absolute Encoder 13 Bit,14 Bit Optical Rotary Encoder
Jilin Lander Intelligent Technology Co., Ltd , https://www.landerintelligent.com