Summary: The database world doesn't have incredible news every week, but in a year, I was surprised to find that we saw a lot of new things and the unremitting development of the field.
As an editor of Database Weekly (Database Weekly is a weekly newsletter about new content in the world of databases and data storage), I like to hang out in the new database system and see what ideas might come in the next few decades. Affects everyday developers.
The database world doesn't have incredible news every week, but in a year, I was surprised to find that we saw a lot of new things and the unremitting development of the field. 2017 is no exception, so I want to review some interesting new releases, including a transactional chart database, a replicable geographic multi-model database, and a new high-performance key/value store database.
TimescaleDB - a Postgres-based time series database with automatic partitioning
One exciting new extension stems from PostgreSQL, an Apache 2.0-based license that was launched with an organization called PhD-packed.
Timescale adds time series storage to Postgres through automatic partitioning, but is included in the usual Postgres interface and tools. Queries are performed using the regular SQL "hypertable" that provides an interface to time series data.

Microsoft Azure Cosmos DB - Microsoft's multimodal database
Cosmos DB is essentially the rebranding and rebuilding of Azure's old DocumentDB brand, but it's easy to cross globally distributed data with Azure's diverse data centers. Global distribution is the killer of Cosmos DB, and it can route database requests to the most recent area containing data without changing the configuration.
The "multi-mode" part is also important. While everything is under the hood of modeless JSON, there is still a SQL query API, as well as the MongoDB API, the Cassandra API, and even a graphical database API (based on Gremlin).
One of the better ways to learn more about Cosmos is a 15-minute video introduction to this Microsoft Channel 9.
Cloud Spanner — Google Global Distributed Relational Database
Google's Cloud Spanner has been working for a long time, initially publicly explained in a very interesting academic paper in 2012 (although development began in 2007). The initial development was because Google needed a globally distributed, highly available storage system, but it is now open to the public.
Google recognizes that the features that make Cloud Spanner suitable for its own use are also attractive to businesses, so it promises 99.999% availability, unplanned downtime, and "enterprise" security.
Cloud Spanner supports ANSI 2011 SQL, providing developers of familiar relational database concepts with a high-availability, relational database that has been combat-tested for high-availability levels.
Neptune - Amazon's comprehensive management of graphical database services
Microsoft and Google have already talked about it, so how can you miss Amazon? This is another database that is limited to a specific cloud service. Amazon presented a preview of Neptune at the recent re:Invent conference.
Neptune promises to be a fast and reliable graphical database service that is designed to quickly provide developers with graphical database services without the hassle of having to pay for them, of course, for a fee.
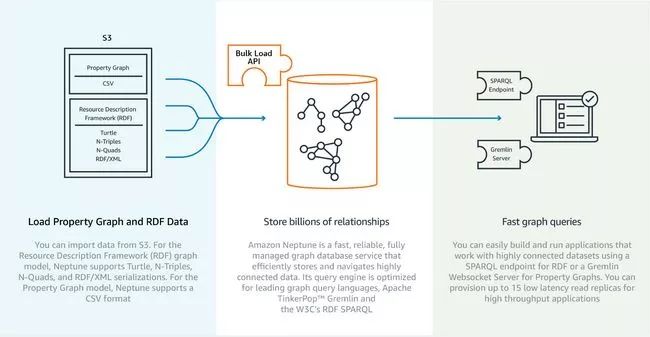
Neptune supports two standards for querying your graphics library. One is Gremlin's "golden" standard, which is getting more and more support, and SPARQL (your graphics will be treated as an RDF).
YugaByte — an open source cloud native database
YugaByte stands out this year for its "stealth mode", which provides a database that supports SQL and NoSQL modes of operation. The goal is to use it directly in the cloud, acting as a stateful complement to the container.
YugaByte is built and open sourced in C++ and supports Cassandra Query Language (CQL) and Redis protocol. Support for the PostgreSQL protocol is in progress and Spark applications can run on it.

YugaByte is another project that was supported after launch (created by a Facebook engineer who extended the Apache HBase platform). Its business model was initially set to have an "enterprise version", adding a cloudy cluster to the open source community version. Features such as coordination, monitoring and alerting, tiered storage and support.
Peloton - a self-driven SQL DBMS
Peloton explored some interesting ideas, especially in the area of ​​using AI to automatically optimize the database. It also supports byte-addressable NVM storage technology and is open sourced using the Apache license.
The idea behind the "self-driven" database is that the DBMS can operate and tweak itself. It predicts the trend of the workload and prepares it accordingly without the need for a DBA or operator control.
Perhaps not surprisingly, Peloton originated from an academic project (especially from Carnegie Mellon University) and one of its founders wrote a series of articles on why it was created. It has been in development for several years, but it has become more open in 2017.
JanusGraph — a Java-based distributed graphics database
JanusGraph is a practical, ready-to-use database with a lot of integration and built on the solid foundation of TitanDB. It is optimized for scalability, storage, and querying large graph databases, while supporting transactions and a large number of concurrent users.
It can use Cassandra, HBase, Google Cloud Bigtable, and BerkeleyDB as storage backends, and can be directly integrated with Spark, Giraph, and Hadoop. It even supports full-text and geo-location retrieval integrated with ElasticSearch, Solr or Lucene.
Aurora Serverless - Instantly scalable, "pay-as-you-go" relational database on AWSAnother announcement from the Amazo re: Invent conference was the serverless version of their successful Aurora database service, Aurora Serverless.
With the latest trend of integration into the "serverless" platform, this platform will forever eliminate your expansion and operational challenges. The idea behind Aurora Serverless is that many database use cases do not require consistent performance or usage levels. Instead, you can " Pay at any time (pay per second) to adjust the size of the database as needed.
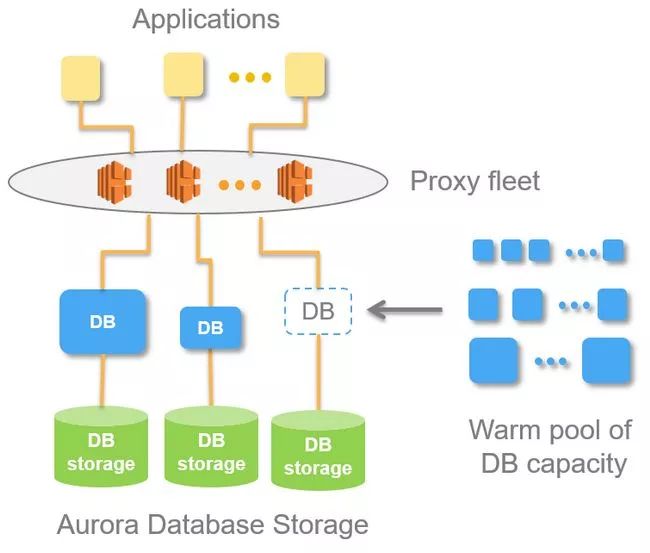
It is currently only a preview version, but promises significant progress in 2018.
TileDB - for storing large density and sparse matrix arraysTileDB is a database from the Massachusetts Institute of Technology and Intel that stores multidimensional array data, a common requirement in areas such as genetics, medical imaging, and financial time series.
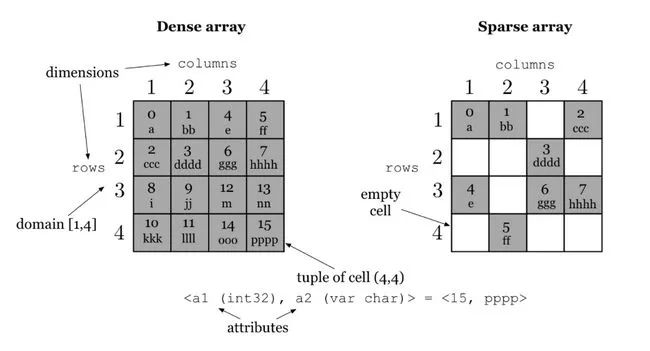
It supports many compression mechanisms (such as gzip, lz4, Blosc, and RLE) and storage backends (such as GFS, S3, and HDFS).
Memgraph - a high performance, memory resident graphics databaseThe driving force behind Memgraph is to provide tools for rapid analysis and use of data from man-made and machine intelligence as well as the growing interconnectivity of devices and the Internet of Things. Therefore, the priority is "speed, scalability and simplicity."
In the life cycle of Memgraph, it is still in its early stages. It is not open source, but can be downloaded via request. It supports the openCypher graphical query language, supports in-memory ACID transactions, and has a disk-based persistence mechanism.
Investment Casting, also known as lost wax casting, includes wax pressing, wax repairing, tree formation, paste, wax melting, casting metal liquid and post-treatment processes. Lost wax casting is the process of making a wax mold of the part to be cast, and then coating the wax mold with mud. After the clay mold is dried, melt the wax mold inside in hot water. Melt the wax mold out of the clay mold and then roast into pottery mold. Once roasted. Generally, a casting port is left when the mold is made, and then molten metal is poured into the pouring port. After cooling, the required parts are made.
Investment Casting,Lost Wax Casting,Steel Investment Casting,Stainless Steel Investment Casting
Tianhui Machine Co.,Ltd , https://www.thcastings.com